How it works
Establishing Job & Task Dependencies
Data processing pipelines are dependent on the resources available across the network, from source system through to target staging area, data warehouse, data lake and more. Executing these pipelines inefficiently can add an overwhelming overhead to the existing infrastructure and cause significant impact and loss of productivity.
To minimise the impact most organisations will have designated processing windows where ETL / ELT jobs can run, but the management and interdependency of them can be complicated.
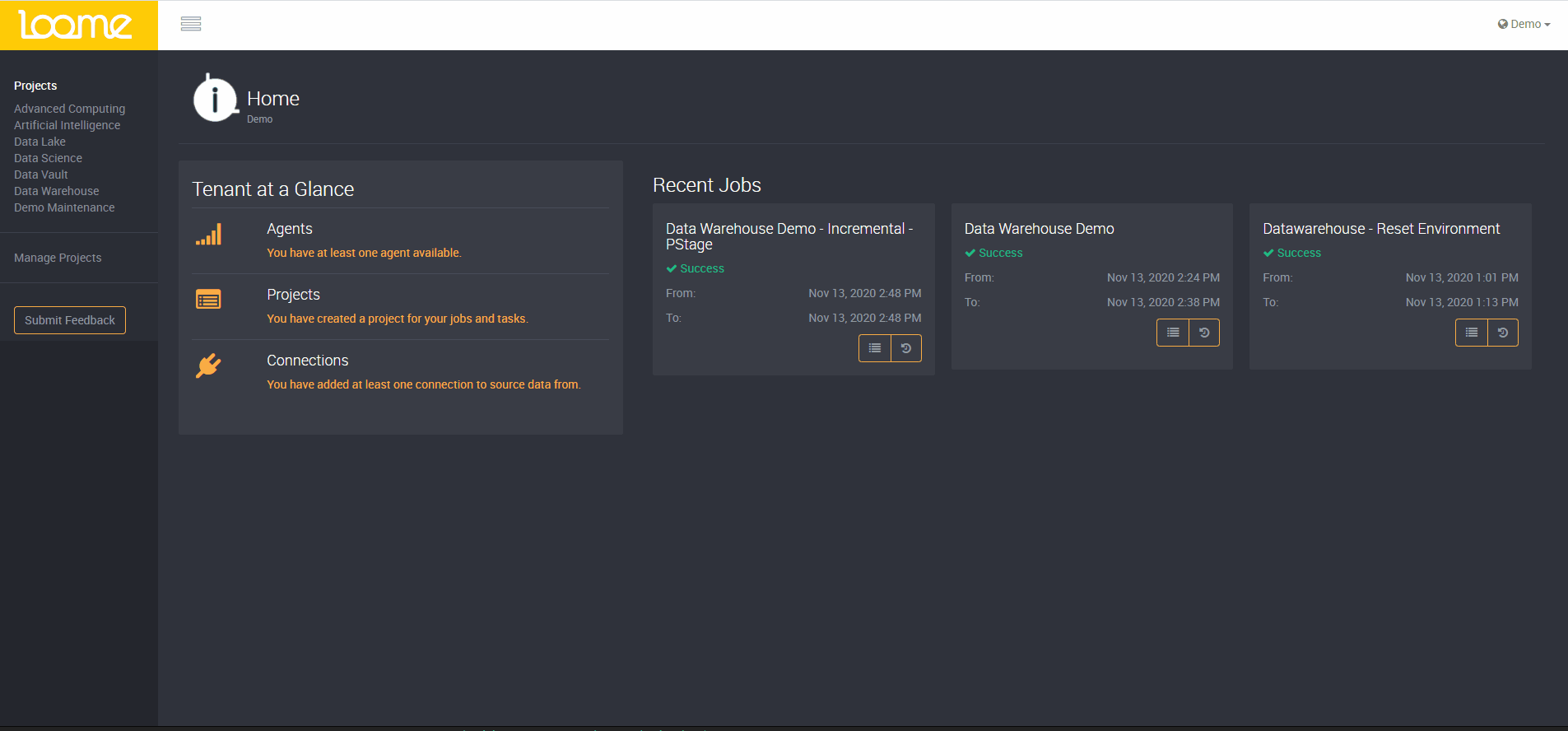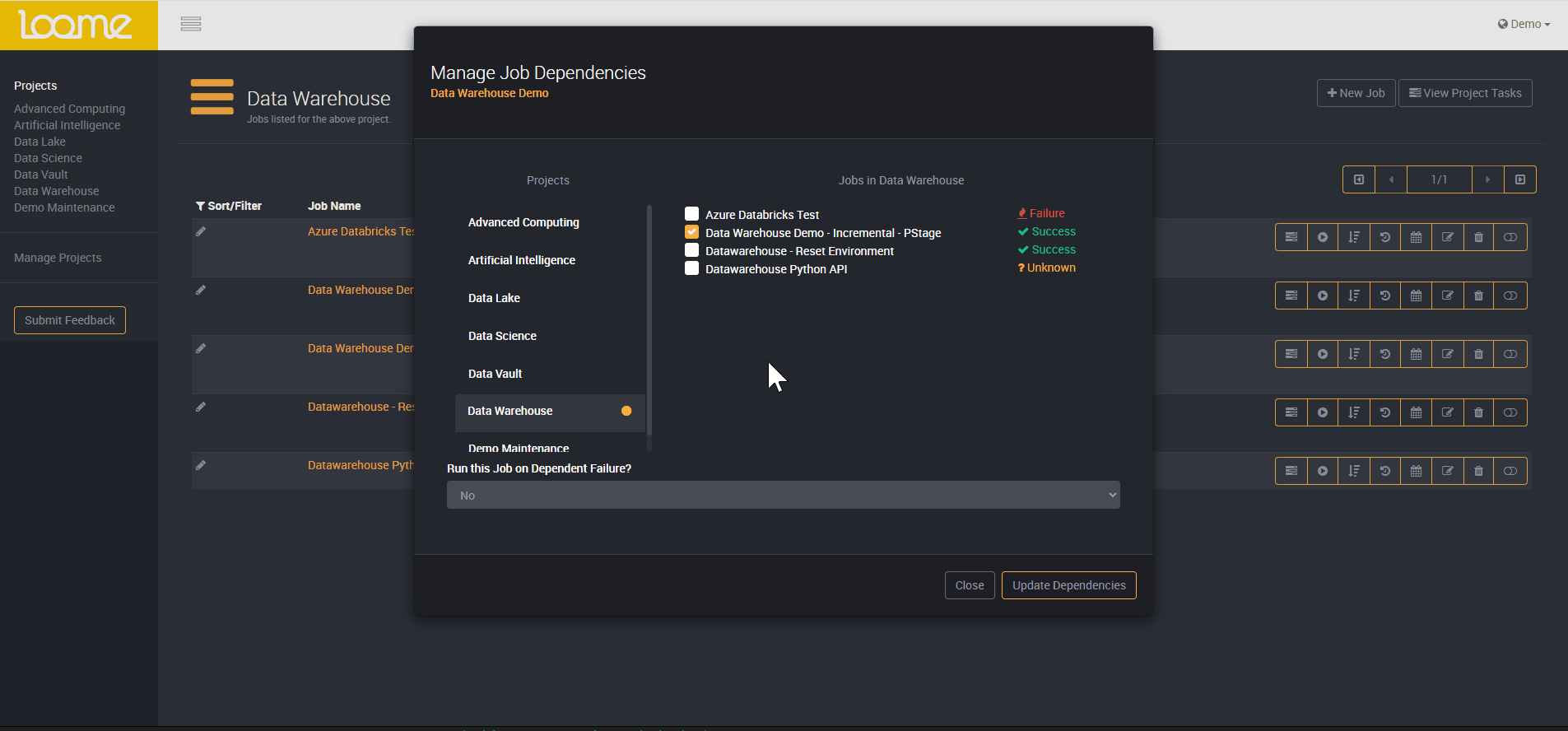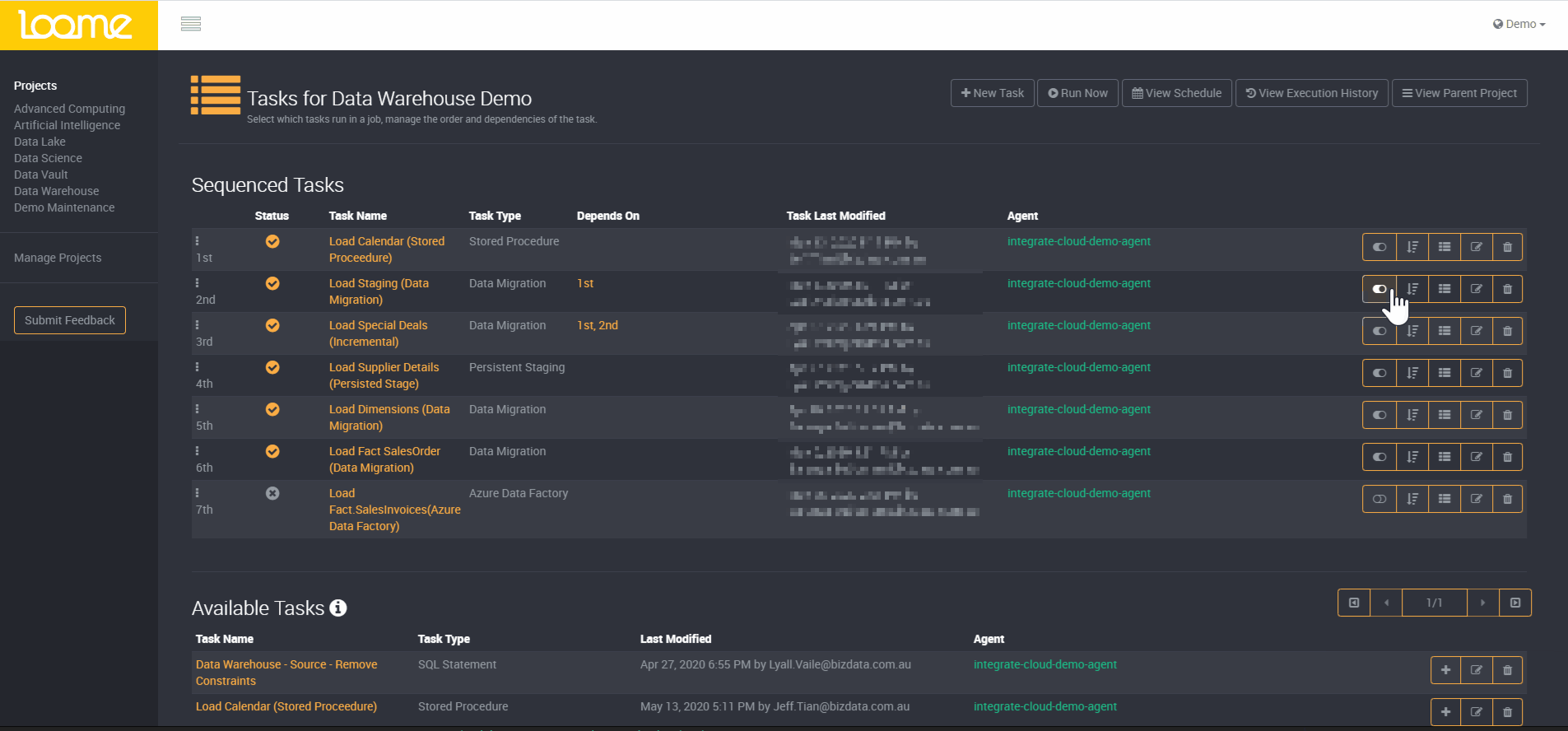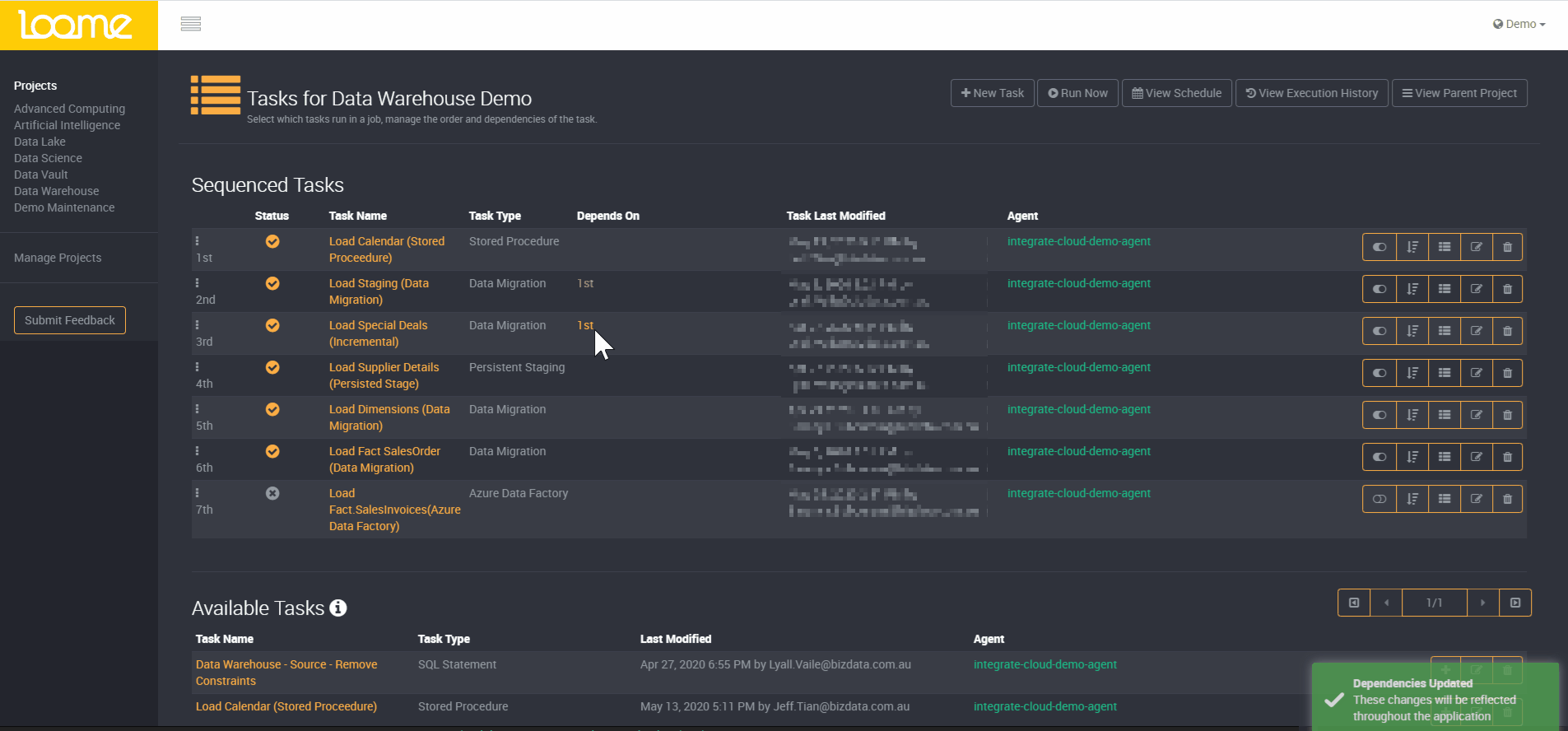
Loome allows you to quickly and easily set up job dependencies without any additional coding required. Depending on how your data warehouse is updated, you may require certain jobs to run and complete before commencing the next job. Dependendant jobs will be held in a 'pending' state, until the job the dependency is configured to completes successfully.
Dependency within tasks works in the same manner. A job may have multiple tasks to execute and some tasks may be reliant on others to ensure data is loaded as expected. When setting up a task in Loome you have the ability to configure the level of parallelism you desire, meaning tasks can be run in parallel to optimise processing times. Loome will automatically process tasks with dependencies in sequence, and manage the processing of remaining tasks in parallel as determined by the scale and scope of supporting infrastructure.